
 进阶
进阶
# Region Server 架构和读写流程
HBase 的基本架构就是 Zookeeper -> Master -> Region Server -> Region -> HDFS。这里重点要说的是 Region Server 的架构。
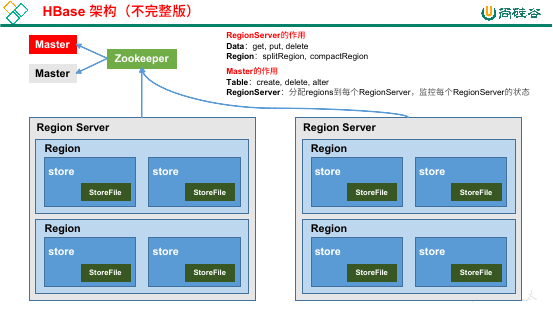
再来回顾一下 region:
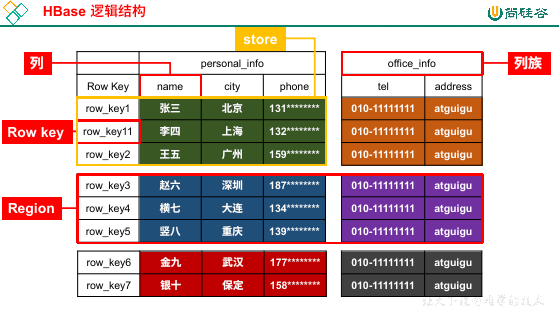
为了解决文件太大的困扰,HBase 会横向切分表,每一块就是一个 Region,而每一个 Region 根据列族进行纵向切分,形成的就是 Store。
为了方便读写,每一个 Region 的内容一定会存储到一台服务器上,而具体存储的物理文件以 Store 为主,也就是说每一个 Store 都是一个 StoreFile(或者叫做 HFile)。
既然每一个 Region 都会存到一台服务器上,那么我们就有 Region Server 的概念:
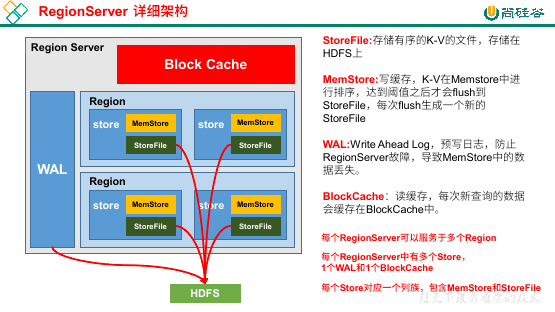
在每个 Region Server 中,可以有多个 Region,一个 WAL(预写日志),一个 Block Cache(读缓存)。每一个 Store 的结构都有一个 MemStore(读写缓存),一个 StoreFile(物理文件)。
写流程
Client 请求 Zookeeper,获取 HBase 的 meta 表位于哪个 Region Server。
访问对应 Region Server,获取 meta,根据请求的 namespace:table/rowKey 获取位于哪个 Region Server 的哪个 Region。
将上面的信息缓存到 Client 的 meta cache,方便下次访问。
与目标 Region Server 进行通信。
将数据顺序追加到 WAL 中(避免意外情况导致数据丢失)。
将数据写入 MemStore,数据会在 MemStore 中进行重新排序(所以 HFile 中的数据是顺序的)。
向客户端发送 ack。
等到 MemStore 满足条件之后,将数据写入到 HFile(每次刷写都会生成一个 HFile),减少 WAL 文件。
单个满足条件的时机:
- 单个 MemStore 大小达到了配置的值
hbase.hregion.memstore.flush.size,默认128M - 单个 MemStore 时间达到了配置的值
hbase.regionserver.optionalcacheflushinterval,默认 1h
总体满足条件的时机:
- Region Server 中总的 MemStore 大小达到了
java_heapsize * hbase.regionserver.global.memstore.size(默认值0.4)* hbase.regionserver.global.memstore.size.lower.limit(默认值0.95),会按照 MemStore 大小由大到小依次刷写,直到 RegionServer 中,MemStore 的总大小减少到上述值以下。 - WAL 文件超过 32,按照时间顺序自动刷写,直到文件数量减少到 32 以下(现在已经无需手动设置)。
停止刷写到 MemStore 的时机:
- 单个 MemStore 大小达到了
hbase.hregion.memstore.flush.size(默认值128M)* hbase.hregion.memstore.block.multiplier(默认值4)将停止向此 MemStore 刷写数据。 - RegionServer 总大小达到了
java_heapsize * hbase.regionserver.global.memstore.size(默认值0.4)会停止向所有 MemStore 写入数据。
- 单个 MemStore 大小达到了配置的值
读流程
Client 访问 Zookeeper,获取 HBase 的 meta 表位于哪个 Region Server。
访问到 meta 表,根据读请求的 namespace:table/rowKey 得到目标所在的 Region Server。
将该信息缓存在 Client 的 meta cache 中。
与目标 Region Server 进行通讯。
查询数据
因为缓存的存在,所以 Block Cache 和 HFile 的数据是相同的,所以假如 Block Cache 中有数据,就不需要从 HFile 中读取。
版本问题也不用考虑,Block Cache 缓存的只是某个版本的数据,假如 Block Cache 存在我们需要某个版本的数据那么直接就返回了,假如需要其他版本的数据,仍然需要读取 HFile。
除了 Block Cache 和 HFile,读数据还有可能在 MemStore 中读取(已经写入 Memory Cache 但是尚未 flush 到 HFile 中的数据)。
注意一点,某条数据可能有多个版本,所以可能会在多个 HFile 中存在,所以可能会读取多个 HFile。
合并数据
因为数据存在多个版本,所以要从 MemStore + Block Cache / HFile,从而得到我们最终想要的版本。
注意一点,MemStore 中的数据虽然是最新的,但是不一定是我们需要的。
比如说,假如 MemStore 想要删除某个版本的数据,这肯定就不是我们想要的结果,所以还需要进行数据合并。
将查询到的数据块(某个版本的数据)缓存到 Block Cache。
结果返回给客户端。
提示
注意,在进行读取 HFile 的过程中,HBase 提供了三种手段进行读取加速。
- 时间范围过滤。在进行读取的时候,首先会根据时间范围过滤 HFile,避免读取不必要的文件。
- RowKey 过滤。根据 RowKey 过滤 HFile,缩小读取范围。
- 布隆过滤器。每个 HFile 都有自己的布隆过滤器,它可以告诉某个文件中没有某条数据。
StoreFile Compaction
之前我们提到过有一种叫做 Region 合并的情况。其实这种说法不太准确,Region 是不能合并的,我们合并的是 Region 中的 HFile。
因为 MemStore 每次 flush 都会产生一个 HFile,所以对于同一条数据,不同版本、不同类型,都可能会存在不同的 HFile 中。
长此以往,读取数据就会在多个文件中读取,速度会下降。为了减少 HFile 的个数,删除的多余数据,HBase 会进行 HFile 的合并,也就是 StoreFile Compaction。
Compaction 分为两种,一种是 Minor Compaction(小合并),一种是 Major Compaction(大合并):
Minor Compaction 会将临近的几个若干个小的 HFile 合并为一个较大的 HFile,并且清理掉部分过期和删除的数据。
在 Minor Compaction 中,清理过期和需要删除的数据只能是一小部分,有些数据它不能确定有用还是没用,只能留着。
每次 flush 数据都有可能产生小合并,但是不一定会,还需要满足一些条件。
Major Compaction 会合并一个 Store 下的所有 HFile 为一个大的 HFile,清理所有过期和删除的数据。
大合并定时合并,默认七天一次,可以进行配置。
Region Split
HBase 在开始只有一个 region,但是当表逐渐增大时,region 会自动切开为多个(当然,在生产环境可能会做预分区优化)。
为了负载考虑,HMaster 可能会将多个 Region 分给多个 Region Server。我们之前提到,每一个 Region 的数据都会存储到一台机器上,这句话没错,但是一张表有可能会分为多个 Region,那多个 Region 就可能分散给不同的 Region Server。
当一个 Region 中的某个 Store 下的 StoreFile 的总大小超过 Min(initialSize * R^3 , hbase.hregion.max.filesize"),此 Region 就会切分。
其中 initialSize 默认为 2 * hbase.hregion.memstore.flush.size,R 为当前 Region Server 中,属于此 Table 的 Region 个数,默认情况下,具体的策略:
- 第一次:
1^3 * 256 = 256MB < 10GB,取值 256MB。 - 第二次:
2^3 * 256 = 2048MB,同理取值 2048MB。 - 第三次:
3^3 * 256 = 6912MB,通离去之 6912MB。 - 第四次:
4^3 * 256 = 16384MB > 10GB,取值较小的 10GB。 - 之后,每次都是 10GB。
因为这种方式比较麻烦,在 HBase2.0 引入了新的策略:假如当前 RegionServer 上,此表只有一个 Region,按照 2 * hbase.hregion.memstore.flush.size 分裂,否则按照 hbase.hregion.max.filesize 分裂。
# API 操作
环境搭建
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.0.5</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.0.5</version>
</dependency>
用户 API 参考 (opens new window)
案例
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.NamespaceDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.After;
import org.junit.Before;
import java.io.IOException;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
/**
* 1. 获取 connection 对象,重量级别实现,打开一直用即可
* 2. 获取 table,DML 操作,随用随打开即可
* 3. 获取 admin,DDL 操作,随用随打开即可
*/
public class HBaseDemo {
private static Connection connection;
@Before
public void config() throws IOException {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "hadoop102,hadoop103,hadoop104");
connection = ConnectionFactory.createConnection(conf);
}
/*------------------------------- DDL -------------------------------*/
public void createNamespace(String namespace) throws IOException {
Admin admin = connection.getAdmin();
// 除了 createNamespace 之外,还可以 list、modify 等,不说了
admin.createNamespace(NamespaceDescriptor.create(namespace).build());
admin.close();
}
/**
* 创建表
*
* @param namespace
* @param tableName 表名称
* @param cfs 列族
*/
public void createTable(String namespace, String tableName, String... cfs) throws IOException {
if (tableExists(namespace, tableName)) {
return;
}
Admin admin = connection.getAdmin();
TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(TableName.valueOf(namespace, tableName));
List<ColumnFamilyDescriptor> columnFamilyDescriptors = Arrays.stream(cfs)
.map(family -> ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(family)).build())
.collect(Collectors.toList());
tableDescriptorBuilder.setColumnFamilies(columnFamilyDescriptors);
TableDescriptor tableDescriptor = tableDescriptorBuilder.build();
admin.createTable(tableDescriptor);
admin.close();
}
public Boolean tableExists(String namespace, String tableName) throws IOException {
Admin admin = connection.getAdmin();
return admin.tableExists(TableName.valueOf(namespace, tableName));
}
public void dropTable(String namespace, String tableName) throws IOException {
if (!tableExists(namespace, tableName)) {
return;
}
Admin admin = connection.getAdmin();
TableName table = TableName.valueOf(namespace, tableName);
// 删除表之前首先需要禁用表
admin.disableTable(table);
admin.deleteTable(table);
admin.close();
}
/*------------------------------- DML -------------------------------*/
/**
* @param namespace
* @param tableName
* @param rowKey
* @param columnFamily 列族
* @param columnName 列的名字
* @param value 数据
*/
public void put(String namespace, String tableName, String rowKey, String columnFamily, String columnName, String value) throws IOException {
Table table = connection.getTable(TableName.valueOf(namespace, tableName));
Put put = new Put(Bytes.toBytes(rowKey));
put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(columnName), Bytes.toBytes(value));
// 可使用重载,放 put 的 list 集合
table.put(put);
table.close();
}
/**
* 删除时,可以指定删除某个 rowKey 的数据,也可以直接删除某个列族的数,也可以直接删除某个列的数据。
* <p>
* columnFamily、columnName 可选
*
* @param namespace
* @param tableName
* @param rowKey
* @param columnFamily
* @param columnName
*/
public void delete(String namespace, String tableName, String rowKey, String columnFamily, String columnName) throws IOException {
Table table = connection.getTable(TableName.valueOf(namespace, tableName));
/*
删除某个 rowKey 对应的数据
HBase 标记为 DeleteFamily,因为这里删除的是一整行的数据,删除的是所有列、所有列族的数据
*/
Delete delete = new Delete(Bytes.toBytes(rowKey));
table.delete(delete);
/*
删除整个列族的数据
HBase 标记为 DeleteFamily,但是由于一行中可能有多个列族,那么没有指定的列族自然不会删除
*/
Delete deleteFamily = new Delete(Bytes.toBytes(rowKey));
delete.addFamily(Bytes.toBytes(columnFamily));
table.delete(deleteFamily);
/*
删除某个列族中的某个列的最后一个版本,HBase 标记为 Delete
除了 addColumn,还可以指定 addColumns(family, column),这个指定的是一个列的所有版本,它的标记为 DeleteColumn
*/
Delete deleteColumn = new Delete(Bytes.toBytes(columnName));
delete.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(columnName));
table.delete(deleteColumn);
table.close();
}
/**
* get 也可以获取某个 rowKey、列族、列的数据
*
* @param namespace
* @param tableName
* @param rowKey
* @param columnFamily
* @param columnName
*/
public void get(String namespace, String tableName, String rowKey, String columnFamily, String columnName) throws IOException {
Table table = connection.getTable(TableName.valueOf(namespace, tableName));
// 拿到一整行数据
Get get = new Get(Bytes.toBytes(rowKey));
Result result = table.get(get);
Arrays.stream(result.rawCells()).forEach(cell -> {
// 直接使用 cell.getRowArray() 的方式有问题,需要工具类转换一下
String rowKeyStr = Bytes.toString(CellUtil.cloneRow(cell));
String columnFamilyStr = Bytes.toString(CellUtil.cloneFamily(cell));
String valueStr = Bytes.toString(CellUtil.cloneValue(cell));
System.out.printf("rowKey %s, columnFamily %s, value %s\n", rowKeyStr, columnFamilyStr, valueStr);
});
// 拿到列族的数据
Get getFamily = new Get(Bytes.toBytes(rowKey));
getFamily.addFamily(Bytes.toBytes(columnFamily));
Result resultFamily = table.get(getFamily);
// 拿到列的数据
Get getColumn = new Get(Bytes.toBytes(rowKey));
getColumn.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(columnName));
Result resultColumn = table.get(getColumn);
table.close();
}
/**
* 扫描表中数据
*
* @param namespace
* @param tableName
* @param startRow 可选,可以指定从表的哪个位置开始扫描
* @param stopRow 可选,可以指定从表的哪个位置结束扫描
*/
public void scan(String namespace, String tableName, String startRow, String stopRow) throws IOException {
Table table = connection.getTable(TableName.valueOf(namespace, tableName));
Scan scan = new Scan();
// 指定从表的哪个位置开始扫描,可选
scan.withStartRow(Bytes.toBytes(startRow));
// 指定从表的哪个位置结束扫描,可选
scan.withStopRow(Bytes.toBytes(stopRow));
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
Arrays.stream(result.rawCells()).forEach(cell -> {
System.out.println(Bytes.toString(CellUtil.cloneValue(cell)));
});
}
scanner.close();
table.close();
}
@After
public void close() throws IOException {
connection.close();
}
}
# HBase 优化
预分区
这个预分区说的是预先分为多个 region,让数据一进来之后就开始负载均衡。假如之后一个 region 数据量很大,HBase 还是会自动拆分的。
建表时手动分区:
create 'staff1','info',SPLITS => ['1000','2000','3000','4000']划分为了 5 个 region 范围:
负无穷 -> 1000、1000 -> 2000、……、4000 -> 正无穷16 进制序列分区:
create 'staff2','info',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}NUMREGIONS指定为要分为 15 个区,SPLITALGO 指定每个分区的范围(使用HexStringSplit这个 16 进制)这个 15 分区按照 16 进制,也就是从
00000000一直到ffffffff,那分区就是负无穷 -> 11111111、11111111 -> 22222222、……、dddddddd -> eeeeeeee、eeeeeeee -> 正无穷rowKey 的设计和预分区是分不开的,假如按照这种内容,为了均匀放到这几个分区中,rowKey 最好也设计为 16 进制。
按照文件进行分区:
create 'staff3','info',SPLITS_FILE => 'splits.txt'这个
splits.txt是我们自己指定的,这里的SPLITS_FILE指定的就是相对路径下的文件。比如我们指定
aaaa cccc bbbb ddddHBase 会首先将文件进行排序,然后进行预分区。
API 创建分区:
public void createTable(String namespace, String tableName, String... cfs) throws IOException { if (tableExists(namespace, tableName)) { return; } Admin admin = connection.getAdmin(); TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(TableName.valueOf(namespace, tableName)); TableDescriptor tableDescriptor = tableDescriptorBuilder.build(); byte[][] spliteKeys = new byte[4][]; spliteKeys[0] = Bytes.toBytes("1000"); spliteKeys[1] = Bytes.toBytes("2000"); spliteKeys[2] = Bytes.toBytes("3000"); spliteKeys[3] = Bytes.toBytes("4000"); admin.createTable(tableDescriptor, spliteKeys); admin.close(); }
RowKey 设计
预分区和 RowKey 密不可分,设计 RowKey 的目的是让数据均匀地进入 region。
原则:
- 唯一性。
- 散列。
- 在保证以上两者后,长度尽量设计地短。
基础优化
HBase 对内存需要大量开销,但是不建议分配大量的堆内存。因为 Full GC 太久会导致 RegionServer 长期处于不可用状态。
假如服务器内存为 128G,给个 16 -> 36 即可。或者给一台服务器为 16 -> 36G,专门跑 HBase 也行。
接下来是 hbase-site.xml 的基础优化。
RegionServer 和 Zookeeper 会话时间:
zookeeper.session.timeout,默认 90000ms(90s),可以减少一点,例如 60s。RegionServer(RPC) 的监听数量:
hbase.regionserver.handler.count,默认为 30。读写操作都是打到 RegionServer 的,假如读写比较高,可以考虑调高此值
Major Compaction:
HFile 大合并,
hbase.hregion.majorcompaction,默认604800000s(七天),可以设置为 0,手动触发大合并。HFile 大小:
HFile 的大小,
hbase.hregion.max.filesize默认10737418240(10G)假如需要运行 MR,可以减少此值,因为一个 region 会对应一个 MapTask,假如单个 region 太大,会导致 MapTask 过长。
优化 HBase 客户端缓存:
hbase.client.write.buffer,默认 2M,用于客户端缓存。增大可减少 RPC 调用次数,但是会消耗更多内存。反之会增加 RPC 调用次数,但是会减少内存。scan 获取的行数:
hbase.client.scanner.caching使用 API 的 scanner 操作时,返回的 result 不是所有的值(如果是所有的值一次性返回就炸了),而是需要迭代,每次迭代都会返回一些数据。
这个参数可以控制每次迭代返回多少行,值越大会消耗越多的内存。
BlockCache 占用 RegionServer 堆内存的比例:
hfile.block.cache.size默认 0.4MemStore 占用 RegionServer 堆内存的比例:
hbase.regionserver.global.memstore.size默认 0.4